
Vom Lernen und Überwachen - Ein Überblick der Machine Learning-Welt
Im Bereich Data Science werden viele Begriffe verwandt, die schnell zu Verwirrung führen können. Daher beschäftigt sich dieser Artikel mit zwei Grundbegriffen, die immer wieder auftauchen und doch in ihrer Bedeutung häufig falsch verwendet werden: Überwachtes (Supervised Learning) und unüberwachtes Lernen (Unsupervised Learning).
Die Bestandteile der Begriffe selbst geben uns bereits Hinweise worum es hier geht: Überwachung bedeutet die Ausführung einer Aufgabe zu beobachten und zu steuern. Auch wenn der zweite Wortbestandteil um das Lernen kreist, so geht es hier nicht um die Überwachung einer lernenden Person als vielmehr um die Überwachung eines lernenden Machine Learning Modells, also eines statistischen Algorithmus.
Überwachtes Lernen (Supervised Learning)
Ein Lehrer überwacht das Lernen seines Schülers, indem er kontrolliert welche Informationen er dem Lernenden gibt. Gleichzeitig hat der Lehrer Erwartungen über das Ergebnis des Lernens. So überprüft er dieses zum Beispiel mit einem Test. Genauso verhält es sich beim überwachten Lernen: Ein lernender Algorithmus versucht eine Hypothese zu finden, die von zuvor bestimmten Inputparametern auf zuvor bestimmte Outputparameter schließen kann. So wie der Lehrer die Lernmaterialien bestimmt, müssen dem Lernalgorithmus nicht nur Daten zum Lernen gegeben werden, sondern auch Erwartungen über das Ergebnis der Daten. Dies funktioniert mit vorklassifizierten Daten. Anhand dieser kann der Algorithmus seine Hypothese ableiten.
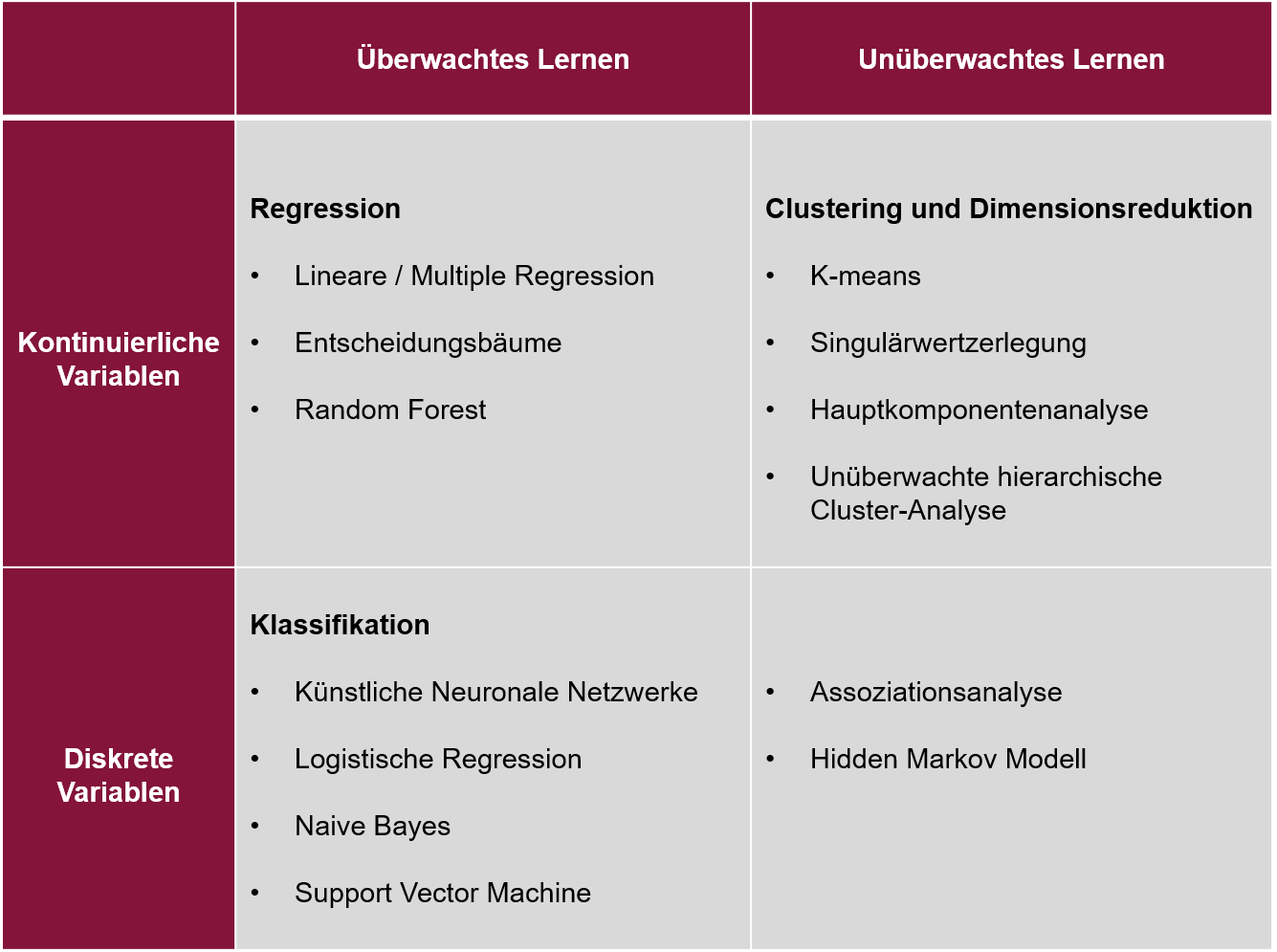
Beim überwachten Lernen werden zwei Arten unterschieden: Klassifikation und Regression. Beide unterscheiden sich in der Art der Outputparameter. Bei einer Klassifikation ist die Outputvariable diskret, erlaubt also eine Einteilung in verschiedene Gruppen. Bei einer Regression ist die Outputvariable kontinuierlich, also numerisch und kann unendlich viele Ausprägungen annehmen.
So wie ein Lehrer seinen Schüler mit einem Test überprüft, können auch die Ergebnisse eines lernenden Algorithmus überprüft werden. Bei Klassifikationen kann überprüft werden, in wieviel Prozent der Fälle die Klassenzuordnung bei einem Übungsdatensatz korrekt erfolgt. Bei Regressionen können die Abweichungen von einer Regressionsgeraden, die sogenannten Residuen, gemessen werden.

Unüberwachtes Lernen (Unsupervised Learning)
Was im Gegensatz dazu ist unüberwachtes Lernen? Wenn wir zum Beispiel in den Klassenraum zurückkehren, finden wir uns nun eher im Unterricht einer Waldorfschule wieder: So legt der Lehrer beim unüberwachten Lernen noch die Schulbücher auf den Tisch, gibt aber weder vor, wofür der Schüler lernen soll noch belohnt oder bestraft er ihn für seine Leistungen mit Noten. So ist es auch beim unüberwachten Lernen von Machine Learning-Modellen: Hier werden zwar die Inputwerte vorgegeben, jedoch sind dem Algorithmus weder Zielwerte bekannt noch wird ihm die Richtung des Lernens vorgegeben, zum Beispiel indem Richtiges verstärkt und falsches abgeschwächt wird. Unüberwachtes Lernen bietet sich daher besonders bei Daten an, die nicht vorklassifiziert sind.
Auch in der Differenzierung von Methoden zum unüberwachten Lernen, spielt die Art der Outputvariablen eine Rolle: Um auf kontinuierliche Variablen zu schließen, werden Methoden zum Clustering und zur Dimensionsreduktion genutzt. Für diskrete Variablen werden assoziative Methoden genutzt. Bei beiden Ansätzen wird der explorative Ansatz von unüberwachtem Lernen deutlich: Aus vorhandenen Daten entsteht eine neue Struktur, sei es nun ein Cluster oder ein Assoziationsmaß; ohne dass vorab ein Ziel oder eine Hypothese bestand.
Am Ende kommt es aber stets darauf an, welches Problem gelöst werden soll und welche Daten vorliegen. Zur Lösung führen beide Wege. So wie beide, ein Schüler in einer regulären Schule und ein Schüler in einer Waldorfschule, trotz ihrer unterschiedlichen Herangehensweisen Erfolg haben können.
