
































Datum: 16.03.2026
Einführung
Die Verwaltung von SQL Server Reporting Services (SSRS) in großen Organisationen kann schnell komplex werden. In meiner Erfahrung mit mehr als 1.000 Finanzberichten - teils über mehrere Regionen, Länder, Datenbanken und Entwicklungsteams hinweg - hat sich eines deutlich gezeigt: Das manuelle Nachverfolgen von Berichtsdefinitionen, Parametern, Abonnements und Ausführungshistorien ist nicht nachhaltig.
Mit dem Wachstum der Reporting‑Landschaft benötigen Administratoren und Entwickler tiefere Einblicke darin, wie Berichte erstellt, geplant, ausgeführt und genutzt werden. Im Folgenden zeige ich auf, wie Sie genau diese Einblicke gewinnen können, indem die SSRS‑ReportServer‑Datenbank direkt abgefragt wird.
Warum herkömmliche SSRS‑Verwaltung nicht ausreicht
Wenn die Anzahl der Berichte steigt, wird das SSRS‑Webportal zunehmend schwer zu verwalten. Das manuelle Durchklicken von Ordnern, um Parameter, Zeitpläne oder Subscription‑Definitionen zu prüfen, ist zeitaufwendig und fehleranfällig.
Für Analysten und Entwickler ist es nicht praktikabel, sich ausschließlich auf das SSRS‑Dashboard zu verlassen, wenn:
- Hunderte Berichte existieren
- Mehrere Teams unterschiedliche Berichte besitzen
- Berichte verschiedene Abteilungen oder Länder bedienen
- Audits, Migrationen oder Archivierungsprojekte erforderlich sind
Ein skalierbarer, systematischer Ansatz ist erforderlich.
Was Sie über Ihre Berichte wissen müssen
Um SSRS effektiv zu verwalten, muss man jede kritische Information analysieren können, darunter:
- Welche SQL‑Anweisungen ein Bericht ausführt
- Wie Berichte geplant werden
- Welche Abonnements definiert sind
- Wer Berichtsdateien erhält
- Welche Parameter verwendet werden
- Ob Ausführungen erfolgreich waren
- Wie häufig Berichte ausgeführt werden
Der zuverlässigste Weg, diese Informationen zu erhalten, ist das Abfragen der ReportServer‑Datenbank.
Ein Blick in die ReportServer-Datenbank
Durch direktes Abfragen der ReportServer‑Datenbank können SSRS‑Administratoren:
✓ Berichtsanfragen und Datenquellen prüfen
✓ Subscription‑Zeitpläne und Zustellmethoden analysieren
✓ Fehlerhafte oder inaktive Abonnements identifizieren
✓ Ausführungshäufigkeit und Leistung überwachen
✓ Ungenutzte Berichte finden
✓ Vollständige Metadaten für Migrationen oder Archivierungen extrahieren
In den letzten zehn Jahren meiner Arbeit mit SSRS habe ich ein Toolkit mit SQL-Abfragen entwickelt, die diese Transparenz leisten. In den folgenden Abschnitten stelle ich die nützlichsten Abfragen vor und erkläre, wann und warum sie verwendet werden sollten.
Praxisbeispiel: Migration eines Reporting-Systems
Ein Kunde migrierte seine Reporting‑Umgebung in die Cloud und ersetzte SSRS durch ein anderes Reporting‑Tool. Dennoch sollten die vorhandenen Datenbanken sowie alle SELECT‑Abfragen der bestehenden SSRS‑Berichte weiterhin verwendet werden.
Die Herausforderung bestand darin, vollständige Metadaten aller Berichte zu extrahieren:
- Alle SQL‑Abfragen
- Alle Datasets und Datenquellen
- Alle Parameter und Subscription‑Definitionen
- Ausführungs‑ und Zustellinformationen
Dies erforderte einen systematischen Ansatz über die ReportServer‑Datenbank.
Schauen wir uns einmal an, wie ich diese Probleme gelöst habe.
1. Extrahieren von Berichtdefinitionen und SQL-Abfragen
Ein manuelles Öffnen von Berichtsdefinitionen in Visual Studio oder Report Builder skaliert nicht gut.
Stattdessen speichert SSRS Berichtsdefinitionen in der Tabelle „ReportServer.dbo.Catalog“ als komprimiertes XML (RDL-Format).
Durch Dekodieren dieses Inhalts können wir alle Berichte programmgesteuert analysieren.
Vollständige Berichtsdefinitionen abrufen
Die folgende Abfrage ruft vollständige RDL-Definitionen zusammen mit Berichtsmetadaten wie Erstellungs- und Änderungsdaten ab:
SELECT
c.ItemID,
c.Name AS ReportName,
c.Path,
c.CreationDate,
c.ModifiedDate,
CAST(CAST(c.Content AS VARBINARY(MAX)) AS XML) AS RDL_XML
FROM ReportServer.dbo.Catalog c
WHERE c.Type = 2; -- Type 2 = Report
Diese Abfrage ruft die rohe RDL-Definition für jeden Bericht ab, einschließlich Metadaten wie Erstellungs- und Änderungsdatum. Diese Ausgabe liefert:
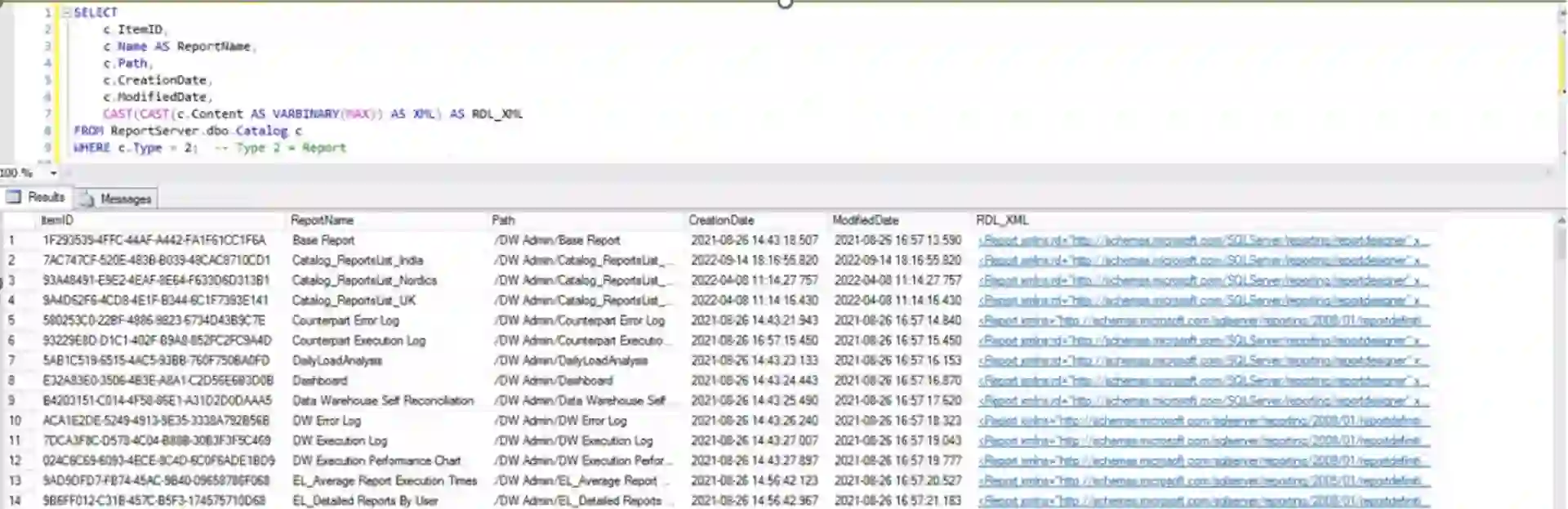
1. Bericht-ID im Katalog
2. Berichtname
3. Berichtpfad im SSRS-Portal
4. Erstellungsdatum
5. Änderungsdatum
6. Vollständige RDL-XML-Definition
Durch Überprüfen der RDL-XML-Datei kann man die vom Bericht verwendeten Datenquellen, Datensätze, Parameter, Beschreibungen und SQL-Abfragen identifizieren.
2. Datasets, SQL Abfragen und Data Sources extrahieren
Der nächste Schritt besteht darin, zentrale SQL-Anweisungen, Datensatzdefinitionen und Datenquellen direkt aus den im Katalog gespeicherten RDL-Dateien zu extrahieren.
;WITH cte AS (
SELECT [path], [name] AS Report_Name,
CONVERT(XML, CONVERT(VARBINARY(MAX), content)) AS rdl
FROM reportserver.dbo.catalog
)
SELECT
LEFT([Path], LEN([path]) - CHARINDEX('/',REVERSE([Path])) + 1) AS Report_Path,
Report_Name,
DataSetNameQ.N.value('@Name', 'nvarchar(128)') AS DataSetName,
DataSrsNameQ.N.value('(*:DataSourceName/text())[1]', 'nvarchar(128)') AS DataSourceName,
ISNULL(DataSrsNameQ.N.value('(*:CommandType/text())[1]', 'nvarchar(128)'), 'T-SQL') AS CommandType,
DataSrsNameQ.N.value('(*:CommandText/text())[1]', 'nvarchar(max)') AS CommandText
FROM cte AS mainSelect
CROSS APPLY mainSelect.rdl.nodes('/*:Report/*:DataSets/*:DataSet') AS DataSetNameQ (N)
CROSS APPLY DataSetNameQ.N.nodes('*:Query') AS DataSrsNameQ (N)
ORDER BY Report_Path, Report_Name, DataSetName, DataSourceName, CommandType, CommandText;
Diese Abfrage liefert u. a.:
- Berichtpfad und ‑name
- Dataset‑Namen
- Datenquelle
- SQL‑Befehl
Unverzichtbar für Audits, Refactoring oder oder die Migration einer großen Anzahl von Berichten.
3. Untersuchen von Subscriptions
Subscriptions automatisieren die Berichtsbereitstellung. Die Daten dazu sind auf mehrere Tabellen verteilt, etwa Subscriptions, ReportSchedule und Schedule.
Grundlegende Subscription Informationen
Die folgende Abfrage extrahiert wichtige Subscription-Details:
SELECT
s.SubscriptionID,
c.Name AS ReportName,
c.Path,
s.Description AS SubscriptionDescription,
s.LastStatus,
s.LastRunTime,
s.DeliveryExtension,
s.EventType,
s.MatchData AS ScheduleDefinition, -- XML
s.Parameters, -- XML
u.UserName AS CreatedBy
FROM ReportServer.dbo.Subscriptions s
JOIN ReportServer.dbo.Catalog c ON s.Report_OID = c.ItemID
JOIN ReportServer.dbo.Users u ON s.OwnerID = u.UserID
ORDER BY c.Name;
Ermöglicht Einblicke in:
- Welche Berichte Abonnements haben
- Zielorte der Ausgabe
- Zeitpunkt der letzten Ausführung
- Erfolg/Fehlschlag
- Eigentümer
Lesbare Zeitplan-Informationen
Um das Planungsverhalten und den Ausführungsstatus besser zu verstehen, liefert die folgende Abfrage lesbare Planungsdetails:
SELECT
c.Name AS ReportName,
c.Path,
s.Description,
s.InactiveFlags,
sch.NextRunTime,
sch.LastRunTime,
sch.LastRunStatus,
s.Parameters
FROM ReportServer.dbo.Subscriptions s
JOIN ReportServer.dbo.Catalog c ON s.Report_OID = c.ItemID
JOIN ReportServer.dbo.ReportSchedule rs ON s.SubscriptionID = rs.SubscriptionID
JOIN ReportServer.dbo.Schedule sch ON rs.ScheduleID = sch.ScheduleID;
Dadurch können Administratoren fehlgeschlagene oder inaktive Abonnements effizient diagnostizieren.
Subscription Inactive Flags
Die Spalte „InactiveFlags“ gibt den Abonnementstatus an oder erklärt, warum es nicht ausgeführt wird:
- 0 – Aktiv
- 1 – E‑Mail oder Dateifreigabe entfernt
- 2 – Fehlende Datenquelle
- 4 – Fehlender Parameter
- 8 – Ungültiger Parameter
- 128 – Vom Benutzer deaktiviert
Subscription-Parameter und -werte
Die folgende Abfrage extrahiert detaillierte Parameterinformationen und bietet Einblick in:
- Parameternamen und -werte
- Ausführungszeitpunkt
- Lieferort oder Empfänger
- Abonnementsprache und -status,
die für Subscriptions definiert sind:
;WITH
[Sub_Parameters] AS
(
SELECT
[SubscriptionID],
[Parameters] = CONVERT(XML,a.[Parameters])
FROM [Subscriptions] a
),
[MySubscriptions] AS
(
SELECT DISTINCT
[SubscriptionID],
[ParameterName] = QUOTENAME(p.value('(Name)[1]', 'nvarchar(max)')),
[ParameterValue] = p.value('(Value)[1]', 'nvarchar(max)')
FROM
[Sub_Parameters] a
CROSS APPLY [Parameters].nodes('/ParameterValues/ParameterValue') t(p)
),
[SubscriptionsAnalysis] AS
(
SELECT
a.[SubscriptionID],
a.[ParameterName],
[ParameterValue] =
(SELECT
STUFF((
SELECT [ParameterValue] + ', ' as [text()]
FROM [MySubscriptions]
WHERE
[SubscriptionID] = a.[SubscriptionID]
AND [ParameterName] = a.[ParameterName]
FOR XML PATH('')
),1, 0, '')
+'')
FROM [MySubscriptions] a
GROUP BY a.[SubscriptionID],a.[ParameterName]
)
SELECT
a.[SubscriptionID],
c.[UserName]AS Owner,
b.Name,
b.Path,
a.[Locale],
a.[InactiveFlags],
d.[UserName] AS Modified_by,
a.[ModifiedDate],
a.[Description],
a.[LastStatus],
a.[EventType],
a.[LastRunTime],
a.[DeliveryExtension],
a.[Version],
e.[ParameterName],
LEFT(e.[ParameterValue],LEN(e.[ParameterValue])-1) as [ParameterValue],
SUBSTRING(b.PATH,2,LEN(b.PATH)-(CHARINDEX('/',REVERSE(b.PATH))+1)) AS ProjectName
FROM
[Subscriptions] a
INNER JOIN [Catalog] AS b
ON a.[Report_OID] = b.[ItemID]
LEFT OUTER JOIN [Users] AS c
ON a.[OwnerID] = c.[UserID]
LEFT OUTER JOIN [Users] AS d
ON a.MODIFIEDBYID = d.Userid
LEFT OUTER JOIN [SubscriptionsAnalysis] AS e
ON a.SubscriptionID = e.SubscriptionID
order by 17;
4. Überwachung des Ausführungsverlaufs
Der Ausführungsverlauf hilft dabei, Leistungsengpässe, ungenutzte Berichte und betriebliche Probleme zu identifizieren.
Ausführungsprotokolle beantworten Fragen wie:
- Welche Berichte wurden heute ausgeführt?
- Welche Ausführungen sind fehlgeschlagen?
- Wie lange dauert die Ausführung von Berichten?
- Welche Berichte werden selten oder nie verwendet?
Neuester Bericht Ausführungen
Die folgende Abfrage ruft detaillierte Ausführungsinformationen ab:
SELECT
InstanceName,
C.Name as ReportName,
COALESCE(CASE(ReportAction)WHEN 11 THEN AdditionalInfo.value('(AdditionalInfo/SourceReportUri)[1]', 'nvarchar(max)')
ELSE C.Path END, 'Unknown') AS ItemPath,
--UserName,
--ExecutionId,
CASE(RequestType)
WHEN 0 THEN 'Interactive'
WHEN 1 THEN 'Subscription'
WHEN 2 THEN 'Refresh Cache'
ELSE 'Unknown'
END AS RequestType,
-- SubscriptionId,
Format,
Parameters,
CASE(ReportAction)
WHEN 1 THEN 'Render'
WHEN 2 THEN 'BookmarkNavigation'
WHEN 3 THEN 'DocumentMapNavigation'
WHEN 4 THEN 'DrillThrough'
WHEN 5 THEN 'FindString'
WHEN 6 THEN 'GetDocumentMap'
WHEN 7 THEN 'Toggle'
WHEN 8 THEN 'Sort'
WHEN 9 THEN 'Execute'
WHEN 10 THEN 'RenderEdit'
WHEN 11 THEN 'ExecuteDataShapeQuery'
WHEN 12 THEN 'RenderMobileReport'
ELSE 'Unknown'
END AS ItemAction,
TimeStart,
TimeEnd,
TimeDataRetrieval,
TimeProcessing,
TimeRendering,
CASE(Source)
WHEN 1 THEN 'Live'
WHEN 2 THEN 'Cache'
WHEN 3 THEN 'Snapshot'
WHEN 4 THEN 'History'
WHEN 5 THEN 'AdHoc'
WHEN 6 THEN 'Session'
WHEN 7 THEN 'Rdce'
ELSE 'Unknown'
END AS Source,
Status,
ByteCount,
[RowCount],
AdditionalInfo
FROM ExecutionLogStorage EL WITH(NOLOCK)
LEFT OUTER JOIN Catalog C WITH(NOLOCK) ON (EL.ReportID = C.ItemID)
- TimeDataRetrieval, TimeProcessing und TimeRendering helfen Engpässe zu isolieren
- Status gibt Auskunft über Erfolg oder Misserfolg
- RequestType beschreibt, ob der Bericht interaktiv vom Benutzer oder im Rahmen eines Abonnements ausgeführt wurde
- Format – Ausgabeformat rendern
- AdditionalInfo im XML-Format hilft Ihnen, Informationen über Skalierbarkeit, Speicherverbrauch, Verarbeitung, Paginierung usw. zu verstehen.
<AdditionalInfo>
<ProcessingEngine>2</ProcessingEngine>
<ScalabilityTime>
<Pagination>0</Pagination>
<Processing>0</Processing>
</ScalabilityTime>
<EstimatedMemoryUsageKB>
<Pagination>5</Pagination>
<Processing>78661</Processing>
</EstimatedMemoryUsageKB>
<DataExtension>
<SQL>1</SQL>
</DataExtension>
<Connections>
<Connection>
<ConnectionOpenTime>261</ConnectionOpenTime>
<DataSets>
<DataSet>
<Name>Main</Name>
<RowsRead>48658</RowsRead>
<TotalTimeDataRetrieval>4167</TotalTimeDataRetrieval>
<ExecuteReaderTime>4165</ExecuteReaderTime>
</DataSet>
</DataSets>
</Connection>
</Connections>
</AdditionalInfo>
Nicht ausgeführte Berichte in den letzten 90 Tagen
Diese Abfrage identifiziert Berichte, die über einen längeren Zeitraum nicht ausgeführt wurden, und hilft dabei, Kandidaten für die Bereinigung oder Archivierung zu ermitteln. Die Ausgabe liefert Ihnen zusätzliche Informationen darüber, wer den Bericht zuletzt ausgeführt hat und auf welche Weise (interaktiv, pro Abonnement usw.).
Natürlich kann die Anzahl der Tage individuell festgelegt werden:
SELECT DISTINCT a.*, l.UserName
FROM (
SELECT c.[name] as reportName,
SUBSTRING(SUBSTRING(path, CHARINDEX('/', path) + 1, LEN(path)),0,
CHARINDEX('/',SUBSTRING(path, CHARINDEX('/', path) + 1, LEN(path)))) Folder,
CASE(RequestType)
WHEN 0 THEN 'Interactive'
WHEN 1 THEN 'Subscription'
WHEN 2 THEN 'Refresh Cache'
ELSE 'Unknown' END AS RequestType,
MAX(l.TimeStart) lastRunDate
FROM Catalog c
INNER JOIN ExecutionLogStorage l ON l.ReportID = c.ItemID
WHERE c.Type NOT IN (1,3,5,8)
AND l.ReportAction IN(1,13)
GROUP BY c.[name],
SUBSTRING(SUBSTRING(path, CHARINDEX('/', path) + 1, LEN(path)),0,
CHARINDEX('/',SUBSTRING(path, CHARINDEX('/', path) + 1, LEN(path)))),
CASE(RequestType) WHEN 0 THEN 'Interactive' WHEN 1 THEN 'Subscription'
WHEN 2 THEN 'Refresh Cache' ELSE 'Unknown' END
HAVING MAX(l.TimeStart) < getdate() - 90
) a
INNER JOIN ExecutionLogStorage l ON l.TimeStart = a.lastRunDate;
Fehlgeschlagene Ausführungen heute
Um Fehler schnell zu identifizieren, verwendet man die folgende Abfrage (einer meiner täglichen Berichte über Berichte):
SELECT
c.Path AS ReportPath,
c.Name AS ReportName,
a.Status,
a.UserName,
a.Parameters,
a.TimeStart,
a.TimeEnd,
a.TimeDataRetrieval,
a.TimeProcessing,
a.ByteCount,
a.[RowCount]
FROM dbo.ExecutionLog AS a WITH(NOLOCK)
INNER JOIN dbo.Catalog AS c WITH(NOLOCK) ON a.ReportID = c.ItemID
WHERE CAST(TimeStart AS DATE) = CAST(GETDATE() AS DATE)
AND [Status] NOT IN ('rsSuccess');
Benutzer- und Berichtsausführungsstatistiken
Das Verständnis darüber, wer Berichte verwendet und wie oft, ist für die Kapazitätsplanung und Governance von entscheidender Bedeutung.
Welche Nutzer heute Berichte ausgeführt haben
SELECT UserName, COUNT(*) AS 'Executions a day'
FROM dbo.ExecutionLog AS a WITH(NOLOCK)
INNER JOIN dbo.Catalog AS c WITH(NOLOCK) ON a.ReportID = c.ItemID
WHERE CAST(TimeStart AS DATE) = CAST(GETDATE() AS DATE)
GROUP BY UserName
ORDER BY 2 DESC;
Anzahl der Berichtsausführungen
SELECT c.Path+'/'+c.Name AS Path, COUNT(*) AS 'Executions a day'
FROM dbo.ExecutionLog AS a WITH(NOLOCK)
INNER JOIN dbo.Catalog AS c WITH(NOLOCK) ON a.ReportID = c.ItemID
WHERE CAST(TimeStart AS DATE) = CAST(GETDATE() AS DATE)
GROUP BY c.Path+'/'+c.Name
ORDER BY 2 DESC;
Diese Abfragen liefern Erkenntnisse über die Nutzungsmuster in Bezug auf Benutzer und Berichte.
Best Practices
- Vor Änderungen stets Konfigurationsdateien sichern
- Vorsichtiges Arbeiten mit XML‑Parsing in RDLs und Subscriptions
- Regelmäßiges Überwachen der Ausführungshistorie
- Aufräumen ungenutzter Berichte und Abonnements
- Dokumentieren von Besitz und Abhängigkeiten
Schlussgedanken
Um große SSRS‑Umgebungen effektiv zu verwalten, reicht die grafische Oberfläche nicht aus. Durch das Abfragen der ReportServer‑Datenbank können Administratoren:
✓ Berichtsanfragen und Datenquellen auditieren
✓ Subscription‑Pläne und Fehler nachverfolgen
✓ Ausführungsleistung und Nutzung überwachen
✓ Ungenutzte oder fehlerhafte Berichte identifizieren
✓ Migrationen und Archivierungsprozesse unterstützen

Sie haben Fragen? Ich freue mich auf Ihre Nachricht!






- 01
- 02
-
