































Orientierter Leitfaden für mehr Klarheit im Metadaten-Dschungel
Wenn Unternehmen wachsen, wächst auch ihre Datenlandschaft oft schneller, als sie verwaltet werden kann. Organisationen müssen verstehen, welche Daten sie besitzen, wo sie liegen, wer sie nutzt und ob sie verlässlich sind. Um dieses Problem zu adressieren, entstand eine neue Kategorie an Softwarelösungen: Data Catalogs.
Doch wer heute eine Lösung auswählen möchte, steht vor einem unübersichtlichen Markt. Begriffe wie „Active Metadata Platform“, „Data Intelligence Platform“ oder „Data Management Platform“ beschreiben oft Produkte mit nahezu identischen Funktionen von anderen Herstellern. Das erschwert den Vergleich und macht strategische Entscheidungen unnötig kompliziert.
Dieser Artikel soll Klarheit schaffen und dabei drei zentrale Fragen beantworten:
- Was macht einen Data Catalog aus?
- Warum ist der Data Catalog Markt so unübersichtlich?
- Was sind die Unterschiede zwischen den verschiedenen Data Catalog Lösungen?
Die Idee des Data Catalogs
Die ursprüngliche Funktion des Data Catalogs war eindeutig: Er sollte ein durchsuchbares Inventar von Datensätzen und zugehörigen Metadaten innerhalb des Unternehmens bereitstellen. Das Ziel war die Steigerung von Transparenz und Governance durch die Bereitstellung einer konsolidierten Bestandsaufnahme aller Datenbestände.
Der Katalog erfasst Metadaten aus verschiedenen Quellen und Systemen, um eine einheitliche Ansicht Ihrer Unternehmensdaten zu generieren. Dies ermöglicht es Anwendern, die Daten nachzuverfolgen, Transformationen zu verstehen und potenzielle Fehlerquellen zu identifizieren. Anwender können gesuchte Daten schnell finden oder neue, geschäftsrelevante Datensätze entdecken.
Diese zentralisierte Metadaten-Ansicht der Datenlandschaft ist das stärkste Argument für einen Data Catalog. Bei korrekter Implementierung dient er als essenzieller Baustein auf dem Weg zur Data-Driven-Organization und als Fundament für ein effektives Datenmanagement.
Über die Jahre hinweg gewann das Thema Data Catalog an Dynamik: zahlreiche neue Anbieter traten in den Markt ein, und bestehende Lösungen adaptierten die grundlegenden Data Catalog-Konzepte.
Anbieter Positionierung und Marketing
Für einen kurzen Überblick haben wir 15 Marketingaussagen verschiedener Anbieter zusammengestellt, die alle die Kernfunktionalität des klassichen Data Catalogs bieten (obwohl die meisten inzwischen zusätzliche Funktionen enthalten).
- The Agentic Data Intelligence Platform
- AI-Powered Data Management Platform
- The Active Metadata Platform
- Connect the Dots in Data & AI
- Unified Governance for Data and AI
- Ready-to-use Data Catalog
- The Data Catalog Platform
- Modern Data Catalog & Metadata Platform
- Data Management Platform for Enterprise Data Excellence
- AI Powered Cloud Data Management
- Responsible AI Governance & Compliance Solutions
- Open-Source Metadata Platform
- A Comprehensive Data Cataloging and Governance Solution
- Trusted Data. Brilliant AI Outcomes.
- AI Data, Cybersecurity & Platform Modernization
Also, welcher Anbieter ist die richtige Wahl?
Die im Oktober 2025 erstellte Liste zeigt, dass die meisten Anbieter Künstliche Intelligenz als aktuelles Thema prominent in ihr Marketing aufgenommen haben. Noch vor drei Jahren wäre ihre Positionierung gänzlich anders ausgefallen. Die Anbieter passen ihre Ausrichtung laufend an, getrieben von technologischen Trends und dem Zwang, sich vom Wettbewerb abzugrenzen. Diese ständige Neupositionierung stiftet jedoch Verwirrung im Markt: Lösungen, die einst als Data Catalogs galten, wurden nacheinander zu Governance-Plattformen, dann zu modernen Metadaten-Hubs und werden aktuell als KI-Plattformen vermarktet.
Analysten-Frameworks
Verschiedene Analysten-Frameworks von Forrester, Gartner und BARC haben in den letzten zehn Jahren durch wechselnde Schwerpunkte zur Komplexität beigetragen. „Governance“, „Aktivierung“ oder „Intelligenz“ wurden abwechselnd als das entscheidende Merkmal von Datenlösungen hervorgehoben, ohne dass ältere Begriffe vollständig aus der Übersicht entfernt wurden.
Dies führt dazu, dass identische Produkte in verschiedenen Berichten unter einer Vielzahl von Bezeichnungen auftauchen, wie z. B. "AI Governance Solutions", "Data Intelligence Solutions", "Enterprise Data Catalogs" oder "Data Governance Solutions". Obwohl solche Marktanalysen eigentlich für Klarheit sorgen sollten, können sie zur Verwirrung beitragen und fördern eine inflationäre Nutzung von Begriffen: Ältere und neuere Terminologien koexistieren ohne klare Abgrenzung oder Kontinuität.
Räumen wir das Chaos auf
Um mit dem Chaos aufzuräumen, werden wir eine Heuristik verwenden, um die verschiedenen Lösungen voneinander zu unterscheiden. Es ist praktischer, Lösungen nach ihren Kernfähigkeiten zu kategorisieren, was hilft, Marketingaussagen von der tatsächlichen Funktionalität zu trennen. Wir schlagen eine dreistufige Einteilung vor, die auf der Entwicklung der Metadatenreife basiert: Der (klassische) Data Catalog, der fortgeschrittene Data Catalog und die Data & Analytics Governance Plattform.
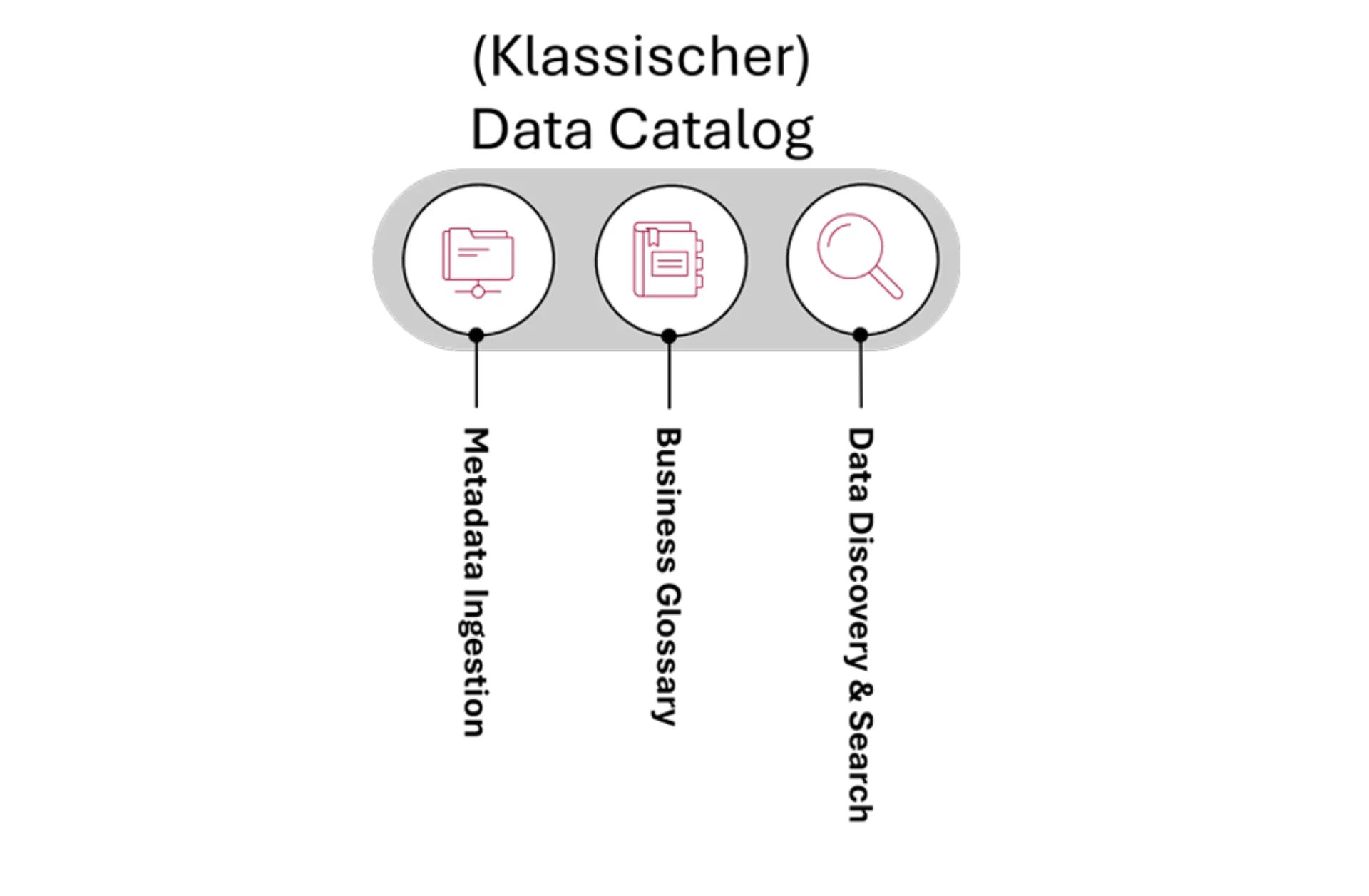
Der (klassische) Data Catalog
Diese erste Kategorie repräsentiert die ursprüngliche Funktion eines Data Catalogs: ein durchsuchbares Verzeichnis von Datenbeständen bereitzustellen. Sein primäres Ziel ist die Transparenz darüber, welche Daten vorhanden sind, und ein gemeinsames Verständnis dieser zu etablieren. In dieser Phase sind Metadaten weitgehend beschreibend und statisch. Sie werden durch eine anfängliche Erfassung (Ingestion) aufgenommen und durch regelmäßige Updates oder manuelle Arbeit gepflegt. Die Capabilites konzentrieren sich vollständig auf diese grundlegende Übersicht:
- Strukturierte Metadatenerfassung aus technischen Quellen und Dokumentation von Data Ownership, Zweck und Definitionen.
- Grundlegende Such- und Entdeckungsfunktionen.
- Bereitstellung eines Business-Glossars für konsistente Terminologie.
Der fortgeschrittene Data Catalog
Für die zweite Kategorie ist am schwierigsten, eine klare Zuordnung der Produkte auf dem Markt vorzunehmen, da in ihr die Grenzen zwischen den verschiedenen Lösungsstufen verwischt werden. Der weiterentwickelte Data Catalog markiert den Übergang von der passiven Dokumentation zum operativen Metadatenmanagement. Hier werden Metadaten dynamisch und automatisch erfasst, kontinuierlich aktualisiert und in tägliche Arbeitsabläufe integriert. Der Fokus verschiebt sich von Transparenz hin zu Benutzerfreundlichkeit und "Governance in Action". Zu den Capabilities, die den (klassischen) Data Catalog erweitern, gehören:
- Automatisiertes Metadaten-Ingestion durch Konnektoren und API-basierte Integrationen.
- Detaillierte Visualisierung der Data Lineage über Systeme und Pipelines hinweg.
- Rollenbasierte Zugriffskontrollen und kollaborative Zertifizierung von Datensätzen.
- Eingebettete Workflows für Annotation, Überprüfung und Freigabe.
- KI-gestützte Vorschläge für Tagging, Klassifizierung und Relevanz von Datensätzen.
Produkte in dieser Kategorie verfügen über die Mehrzahl, aber nicht zwingend, über alle der oben genannten Funktionen. Auch die Tiefe und Qualität dieser neuen Funktionen insbesondere Lineage und Workflow kann von Anbieter zu Anbieter stark variieren.
Bei erfolgreicher Implementierung steigert diese Schicht das Vertrauen in Daten. Durch die direkte Einbettung von Metadaten in Analyse- und Governance-Workflows bauen Unternehmen Silos zwischen Datenproduzenten und -Konsumenten ab. Dies ermöglichten eine schnellere Data Discovery, eine verbesserte Qualitätssicherung und erweiterte Self-Service-Analytics.

The Data & Analytics Governance Platform
Diese letzte Kategorie stellt die fortgeschrittenste Stufe dieser Lösungen dar. Wie es schon bei den Marketingaussagen weiter oben ersichtlich wurde, wählen die meisten Anbieter heute die Bezeichnung "Plattform" oder "Datenmanagement-Lösung". Das spiegelt diese Art von Lösung auch tatsächlich besser wider. Auf dieser Stufe ist der Data Catalog (wie in der ersten Kategorie definiert) als ein Teil oder eine Funktion einer viel breiteren Plattform integriert. Das Charakteristikum der Kategorie ist aber, dass Metadaten kontinuierlich analysiert, angereichert und zur Entscheidungsunterstützung genutzt. Die Plattformen sind darauf ausgelegt, alle Arten von Rollen in einem Unternehmen anzusprechen, von Führungskräften bis hin zur IT.
Zu den Capabilites gehören:
- Echtzeitverarbeitung von aktiven Metadatenströmen zur Anomalie Erkennung und Optimierung.
- Umfassende End-to-End-Lineage, Impact Analysis und die Einhaltung gesetzlicher Vorschriften unterstützt.
- Modelle des maschinellen Lernens, die Nutzungsmuster, vorhersagende Empfehlungen und semantischen Kontext ableiten.
- Einheitliche Dashboards für Observability, Qualität und Compliance.
Hier geht die Rolle der Metadaten über ihre beschreibende Funktion hinaus und wird zu einem aktiven Treiber für den Geschäftswert. Sie ermöglichen vorausschauende Governance, automatisierte Qualitätskontrolle und schnellere, datengestützte Entscheidungen. Das Unternehmen erreicht einen Zustand in den Metadaten nicht nur das Datenökosystem des Unternehmens beschreiben, sondern es auch aktiv optimieren.

Fazit: Wurde das Chaos beseitigt?
Ja und nein. Wir haben ein verbessertes Verständnis geschaffen für den Data Catalog-Markt und die zurückliegenden Entwicklungen, die eine Vielfalt und zahlreichen Lösungen erzeugt haben. Klar ist aber auch: Das "Chaos" selbst kann nicht vollständig beseitigt werden. Der Markt bleibt dynamische und fragmentiert.
Die drei in diesem Artikel beschriebenen Stufen der klassische Data Catalog, der fortgeschrittene Data Catalog und die Data & Analytics Governance Plattform dienen als praxisorientierter, fähigkeitsbasierter Ansatz zur Marktdurchdringung. Sie unterstützen dabei, einen strukturierten Überblick zu gewinnen und die richtigen Fragen zu stellen. Durch die Fokussierung auf die benötigten Capabilities wird es leichter, ausgewählte Lösungen zu bewerten und zu erkennen, inwieweit sie zu den spezifischen Anforderungen der Organisation passen.
